

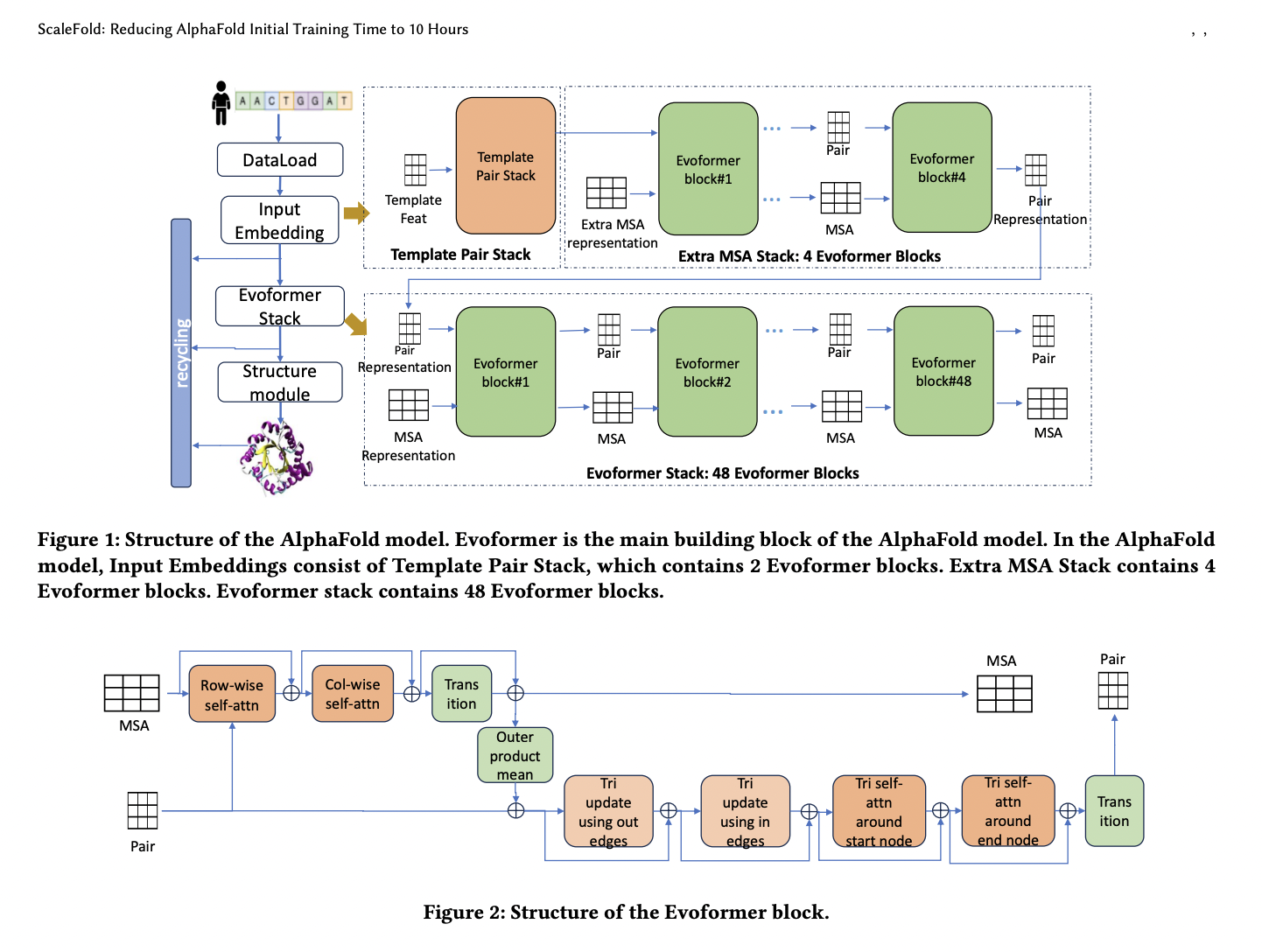
In recent years, deep learning has been effective in high-performance computing. Surrogate models continue to advance, surpassing physics-based simulations in accuracy and utility. This AI-driven progress is evident in protein folding, exemplified by RoseTTAFold, AlphaFold2, OpenFold, and FastFold, democratizing protein structure-based drug discovery. AlphaFold, a breakthrough by DeepMind, achieved accuracy comparable to experimental methods, addressing a longstanding biological challenge. Despite its success, AlphaFold’s training process, relying on a sequence attention mechanism, is time and resource-intensive, hindering research speed. Efforts to enhance training efficiency, such as those by OpenFold, DeepSpeed4Science, and FastFold, target scalability, a pivotal challenge in accelerating AlphaFold’s training.
Incorporating AlphaFold training into the MLPerf HPC v3.0 benchmark underscores its importance. However, this training process presents significant challenges. Firstly, despite its relatively modest parameter count, the AlphaFold model demands extensive memory due to Evoformer’s unique attention mechanism, which scales cubically with input size. OpenFold addressed this with gradient checkpointing but at the expense of training speed. Additionally, AlphaFold’s training involves a multitude of memory-bound kernels, dominating computation time. Also, critical operations like Multi-Head Attention and Layer Normalization consume substantial time, limiting the effectiveness of data parallelism.
NVIDIA researchers provide a study that thoroughly analyzes AlphaFold’s training, identifying key impediments to scalability: inefficient distributed communication and underutilization of compute resources. The researchers propose several optimizations. They introduce a non-blocking data pipeline to alleviate slow-worker issues and employ fine-grained optimizations, such as utilizing CUDA Graphs to reduce overhead. Also, they design specialized Triton kernels for critical computation patterns, fuse fragmented computations, and optimize kernel configurations. This optimized training method, named ScaleFold, aims to enhance overall efficiency and scalability.
The researchers extensively examine AlphaFold’s training, identifying barriers to scalability across communication and computation. Solutions include a non-blocking data pipeline and CUDA Graphs to mitigate communication imbalances, while manual and automatic kernel fusions enhance computation efficiency. They addressed issues like CPU overhead and imbalanced communication, proposing optimizations such as Triton kernels and low-precision support. Asynchronous evaluation and caching alleviate evaluation time bottlenecks. AlphaFold training is scaled to 2080 NVIDIA H100 GPUs through systematic optimizations, completing pretraining in 10 hours.

Comparing ScaleFold to public OpenFold and FastFold reveals superior training performance. On A100, ScaleFold achieves step times of 1.88s for DAP-2, outperforming FastFold’s 2.49s and far surpassing OpenFold’s 6.19s without DAP support. On H100, ScaleFold exhibits step times of 0.65s for DAP-8, significantly faster than OpenFold’s 1.80s with NoDAP. Comprehensive evaluations demonstrate ScaleFold’s advancements, achieving up to 6.2X speedup compared to reference models on NVIDIA H100. MLPerf HPC 3.0 benchmarking on Eos further confirms ScaleFold’s efficiency, reducing training time to 8 minutes on 2080 NVIDIA H100 GPUs, a 6X improvement over reference models. Training from scratch on ScaleFold completes AlphaFold pretraining in under 10 hours, showcasing its accelerated performance.
The key contributions of this research are three-fold:
- Researchers identified the key factors that prevented the AlphaFold training from scaling to more compute resources.
- They introduced ScaleFold, a scalable and systematic training method for the AlphaFold model.
- They empirically demonstrated the scalability of ScaleFold and set new records for the AlphaFold pretraining and the MLPef HPC benchmark.
To conclude, This research addressed the scalability challenges of AlphaFold training by introducing ScaleFold, a systematic approach tailored to mitigate inefficient communications and overhead-dominated computations. ScaleFold incorporates several optimizations, including FastFold’s DAP for GPU scaling, a Non-Blocking Data Pipeline to address batch access inequalities, and a CUDA Graph to eliminate CPU overhead. Also, efficient Triton kernels for critical patterns, automatic fusion via torch compiler, and bfloat16 training are implemented to reduce step time. Asynchronous evaluation and an evaluation dataset cache alleviate evaluation time bottlenecks. These optimizations enable ScaleFold to achieve a training convergence time of 7.51 minutes on 2080 NVIDIA H100 GPUs in MLPerf HPC V3.0, demonstrating a 6X speedup over reference models. Training from scratch is reduced from 7 days to 10 hours, setting a new record in efficiency compared to prior works.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit


Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.

Wanda Parisien is a computing expert who navigates the vast landscape of hardware and software. With a focus on computer technology, software development, and industry trends, Wanda delivers informative content, tutorials, and analyses to keep readers updated on the latest in the world of computing.
